
이번에 회복성(Resilience), SPOF(Single Point Of Failure), 분산 트랜잭션과 결과적 일관성을 공부하면서,
단순 개념 정리보다는 직접 참여했던 프로젝트에 대입해 돌아보는 방식으로 정리했다.
대상 프로젝트는 물류 대행 서비스를 MSA로 구현한 숙련 프로젝트이며, 나는 그 중 주문 도메인을 맡았다.
개념을 배운 뒤 "우리 프로젝트의 어디가 문제였지?"를 짚어보지 않으면 금방 잊히기 때문에,
각 섹션은 개념 → 프로젝트 적용 → 문제 발견 → 개선 방향 순으로 전개했다.
빠른 개념 정리
- 회복성(Resilience): Resilience4j(R4j)를 사용해 마이크로서비스 간 호출 실패 시 재시도하거나, 타임아웃 상황에서 장애 전파를 차단(서킷브레이커)할 수 있다. 그 외 벌크헤드(격리), 레이트 리미터(속도 제한) 기능도 있다.
- SPOF(Single Point Of Failure): 특정 기능을 수행하는 서버가 단 한 대일 때, 그 서버가 다운되면 의존하는 모든 서비스가 함께 장애를 겪는 것이다. MSA 환경에서 이중화와 무상태성이 중요한 이유다.
- 분산 트랜잭션: 모놀리식에서는 하나의 트랜잭션으로 처리되던 비즈니스 로직이, MSA에서는 물리적으로 떨어진 여러 서버의 트랜잭션들로 나뉜다. 따라서 분리된 DB들 간의 데이터 정합성을 맞추는 과정이 별도로 필요하다.
- 결과적 일관성(Eventual Consistency): "지금 당장 모든 곳의 데이터가 일치하지 않더라도, 시간이 지나면 결국 일치하게 된다"는 개념이다. 은행 송금 시 내 잔액은 즉시 차감되지만 상대방 통장 반영까지 수 초의 시차가 생기는 것이 대표적인 예다.
SPOF 관점

위 사진은 숙련 프로젝트의 인프라 설계도다. 물류 대행 서비스에 맞게 사용자 - 업체 - 상품 - 허브 - 주문 - 배송 - AI/알림, 총 7개의 서비스 서버로 구성했다. (지금 보니 상품 서버가 빠져 있다...)
MSA 환경 구성을 위해 유레카, 게이트웨이, 컨피그, 카프카 서버가 연결되어 있고, 각 서비스는 PostgreSQL DB를 개별로 가진다. 이 설계를 SPOF 관점에서 뜯어보면 취약점이 여러 곳에 보인다.
- 인프라 서버들 (유레카, 컨피그, Redis) 모두 단일 서버로 구성되어 있다. 하나라도 다운되면 모든 서비스에 연쇄 장애가 발생한다. 이중화를 통해 고가용성을 확보해야 한다.
- 각 서비스 서버 (주문, 배송, 허브 등) 마찬가지로 서버가 각 1대씩이라 SPOF에 취약하다. 서비스 서버도 이중화가 필요하다.
- NAT가 단일 장애점이 되면 모든 마이크로서비스의 아웃바운드 통신이 중단된다. NAT Gateway Private Subnet의 모든 서버가 외부와 통신(외부 API 호출, 라이브러리 업데이트 등)할 때 이 NAT를 거치기 때문이다. 각 가용 영역(AZ)별로 NAT Gateway를 분산 배치하는 방식이 권장된다.
- PostgreSQL DB 현재 서버마다 1대씩 배치되어 있다. DB 자체도 다중화(레플리케이션 등)를 고려해야 한다.
- 배포 전략 한 서버에만 배포하면 배포 중 장애가 발생할 수 있다. 블루-그린 배포 같은 방식을 도입해야 무중단 배포가 가능하다.
참고로 ALB는 AWS가 관리하는 서비스라 자체적으로 고가용성이 보장된다.
회복성 관점
회복성 관점에서 프로젝트를 돌아보기 전에, 우리 팀이 어떤 설정으로 Resilience4j를 적용했는지 먼저 살펴보자.
설정을 하나씩 짚으면서 각 옵션이 실제로 어떤 장애 상황을 막아주는지 연결해 정리했다.
의존성 추가
api "io.github.resilience4j:resilience4j-spring-boot3:2.2.0"
api 'io.github.resilience4j:resilience4j-circuitbreaker'
api 'io.github.resilience4j:resilience4j-retry'설정 파일 (config-server에서 받아오는 yml)
spring:
cloud:
loadbalancer:
ribbon:
enabled: false # Netflix Ribbon 대신 Spring Cloud LoadBalancer 사용
openfeign:
circuitbreaker:
enabled: true
circuitbreaker:
resilience4j:
enabled: true # Resilience4j 회로 차단기 활성화
# 공통 템플릿(모든 인스턴스의 기본 값)
configs:
default: # 기본 회로 차단기 설정
slidingWindowType: COUNT_BASED # 호출 횟수 기반으로 슬라이딩 윈도우 설정 (TIME_BASED도 가능)
slidingWindowSize: 100 # 상태 결정을 위해 고려할 최근 호출 수
minimumNumberOfCalls: 10 # 회로 차단기가 결정을 내리기 위한 최소 호출 수
permittedNumberOfCallsInHalfOpenState: 10 # 반개방 상태에서 허용되는 호출 수
failureRateThreshold: 50 # 실패율이 50%를 초과하면 회로 차단 (% 기준)
waitDurationInOpenState: 30s # 회로가 열린 상태로 유지되는 시간 (30초)
recordExceptions: # 실패로 간주할 예외 목록
- java.lang.RuntimeException
- org.springframework.web.client.HttpServerErrorException
feign:
client:
default: # 공통 설정
connectTimeout: 5000
readTimeout: 5000
loggerLevel: full
# Resilience4j 개별 모듈 설정 (Retry, Bulkhead, RateLimiter)
resilience4j:
retry: # 재시도 설정
configs:
default: # 기본 재시도 설정
maxAttempts: 3 # 최대 3회 재시도
waitDuration: 1s # 재시도 간 1초 대기
enableExponentialBackoff: true # 지수 백오프 활성화 (재시도마다 대기 시간 증가)
exponentialBackoffMultiplier: 2.0 # 각 재시도마다 대기 시간이 2배로 증가
retryExceptions: # 재시도할 예외 목록
- java.lang.RuntimeException
bulkhead: # 벌크헤드 설정 (동시 호출 제한)
configs:
default: # 기본 벌크헤드 설정
type: THREADPOOL # 스레드풀 타입 벌크헤드 사용 (SEMAPHORE 대신)
coreThreadPoolSize: 5 # 스레드풀의 기본 스레드 수 (항상 활성 상태로 유지)
maxThreadPoolSize: 10 # 스레드풀의 최대 스레드 수 (부하 증가 시 확장)
queueCapacity: 50 # 모든 스레드가 사용 중일 때 대기할 수 있는 요청 수
ratelimiter: # 속도 제한 설정
configs:
default: # 기본 속도 제한 설정
limitForPeriod: 50 # 주기당 최대 50개 요청 허용
limitRefreshPeriod: 1s # 제한이 1초마다 초기화됨
timeoutDuration: 0ms # 허가 대기 시간 (0ms는 대기 없이 즉시 거부)
management:
endpoints:
web:
exposure:
include: refresh,health,info,metrics
logging:
level:
feign: DEBUG이 yml에서 핵심 설정 세 가지를 뽑아 설명했다.
1) 서킷브레이커 활성화
openfeign:
circuitbreaker:
enabled: true2) 서킷브레이커가 장애로 판단하는 기준
configs:
default:
slidingWindowType: COUNT_BASED
slidingWindowSize: 100
minimumNumberOfCalls: 10
permittedNumberOfCallsInHalfOpenState: 10
failureRateThreshold: 50
waitDurationInOpenState: 30s
recordExceptions:
- java.lang.RuntimeException
- org.springframework.web.client.HttpServerErrorException- slidingWindowType: COUNT_BASED: 최근 100번의 호출을 기준으로 통계를 낸다.
- minimumNumberOfCalls: 10: 데이터가 너무 적을 때 성급하게 판단하지 않도록, 최소 10번 호출 후에 실패율을 계산한다.
- failureRateThreshold: 50: 10번 중 5번 이상 실패하면 회로를 OPEN(차단) 한다.
- waitDurationInOpenState: 30s: 회로가 차단되면 30초 동안은 API를 호출하지 않고 즉시 Fallback을 실행한다.
3) Retry, Bulkhead, RateLimiter
resilience4j:
retry:
configs:
default:
maxAttempts: 3
waitDuration: 1s
enableExponentialBackoff: true
exponentialBackoffMultiplier: 2.0
retryExceptions:
- java.lang.RuntimeException
bulkhead:
configs:
default:
type: THREADPOOL
coreThreadPoolSize: 5
maxThreadPoolSize: 10
queueCapacity: 50
ratelimiter:
configs:
default:
limitForPeriod: 50
limitRefreshPeriod: 1s
timeoutDuration: 0ms- Retry: 실패해도 바로 포기하지 않고 최대 3번 재시도한다. 지수 백오프(multiplier: 2.0)로 간격을 1초→2초→4초 순으로 늘려 서버 부담을 줄인다.
- Bulkhead: 특정 서비스(예: Company Service)가 느려져도 전체 스레드가 점유되지 않도록 스레드 풀을 분리한다. Company Service 호출은 최대 10개의 스레드로 제한된다.
- RateLimiter: 초당 50개를 초과하는 요청은 즉시 차단한다. 과도한 트래픽으로부터 서비스를 보호한다.
Feign 타임아웃 설정
feign:
client:
default:
connectTimeout: 5000
readTimeout: 5000서킷브레이커가 개입하기 전에, Feign 레벨에서 5초 동안 응답이 없으면 먼저 연결을 끊는다.
R4j의 slowCallDurationThreshold와 맞춰서 설정해야 하는 값인데,
현재 5초는 꽤 넉넉한 편이다.
코드 적용 예시: CompanyClient 인터페이스 & FallbackFactory
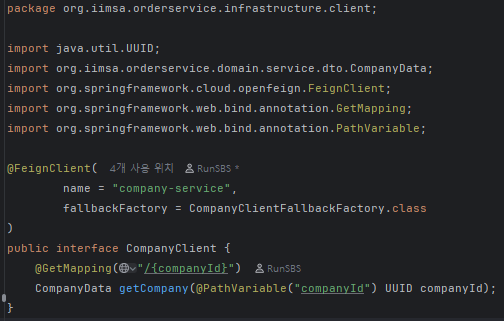
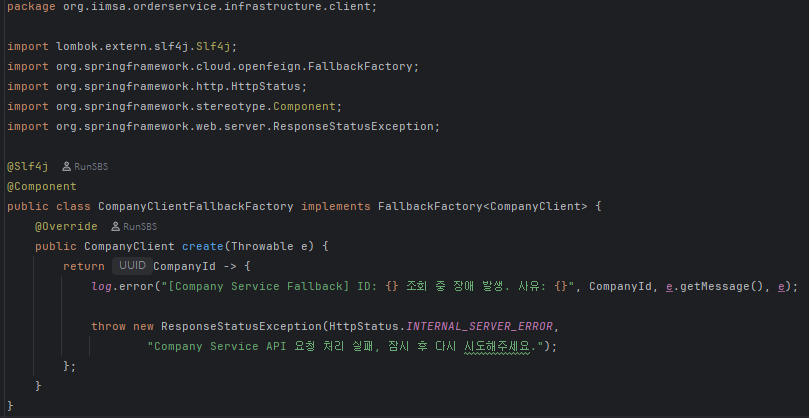
이렇게 설정은 마쳤지만, 시간 관계상 실제 동작 여부를 테스트해보지는 못했다.
아래는 설정값을 토대로 예상되는 동작 시나리오를 정리한 것이다.
R4j 서킷브레이커 & 재시도 시나리오 요약
| 정상 | YES | 정상적인 CompanyData 반환 | CLOSED |
| 일시적 오류 | YES (최대 3번 재시도) | 최종 실패 시 Fallback 실행 | CLOSED (실패율 계산 중) |
| 장애 지속 (실패율 50%) | NO (즉시 차단) | 즉시 Fallback 실행 | OPEN |
| 30초 경과 후 | YES (10번만 허용) | 성공 시 복구 / 실패 시 재차단 | HALF-OPEN |
분산 트랜잭션 관점
허브 관리자가 주문을 생성하고 배송이 출발하기까지 필요한 과정은 다음과 같다.
- 주문 서버에서 주문이 생성된다.
- 주문이 확정되어 허브 서버로 주문 확정 이벤트를 발행한다.
- 허브 서버에서 주문서, 허브 경로, 배송 담당자 정보를 취합한다.
- 배송 서버로 배송 생성 요청 이벤트를 발행한다.
이 흐름에서 분산 트랜잭션 문제가 어떻게 발생하는지를 두 가지 관점으로 나눠 살펴본다.
하나는 FeignClient 호출 재시도, 다른 하나는 이벤트 발행/수신 관점이다.
1) FeignClient 호출과 재시도

주문을 생성하려면 상품 정보와 업체 정보가 필요하다. 이를 FeignClient GET 요청으로 각 서버에서 받아온다.
단순히 상대 서버가 다운된 경우라면 예외가 던져지고 롤백된다.
문제는 일시적인 장애 상황에서의 재시도 흐름이다.
(주문 → 업체)Feign GET 실패 →
FallbackFactory 예외 던짐 →
@Retry가 가로채어 재시도 →
3회 모두 실패 시 fallbackMethod 실행 →
최종 예외 발생@Retry를 어느 쪽에 두느냐에 따라 동작 방식이 달라진다.
호출하는 쪽(주문 서비스)에서 @Retry를 설정하는 경우
@Component
@RequiredArgsConstructor
public class CompanyProvider {
private final CompanyClient companyClient;
@Retry(name = "company-service", fallbackMethod = "getCompanyFallback")
public CompanyData getCompanyData(UUID id) {
return companyClient.getCompany(id);
}
public CompanyData getCompanyFallback(UUID id, Throwable t) {
log.error("최종 재시도 실패: {}", id);
throw new RuntimeException("업체 서버 연결 불가");
}
}[주문 서비스] → (재시도 주도) → [업체 서비스]
- 누가 노력하나: 주문 서비스가 재시도를 주도한다.
- 언제 쓰나: 네트워크 장애, 타임아웃, 상대 서버 다운처럼 호출 자체가 실패했을 때.
- 특징: 상대 서버가 꺼져 있어도 주문 서비스가 재연결을 시도할 수 있다.
- 주의점: 재시도 동안 스레드가 점유되어 유저 대기 시간이 길어진다.
호출 당하는 쪽(업체 서비스)에서 @Retry를 설정하는 경우
@Service
public class CompanyService {
@Transactional(readOnly = true)
@Retry(name = "company-db-retry", fallbackMethod = "handleCompanyRetryFailure")
public CompanyResponse getCompanyDetails(UUID companyId) {
// DB 조회 or 외부 API 호출
}
public CompanyResponse handleCompanyRetryFailure(UUID companyId, Throwable t) {
throw new ResponseStatusException(HttpStatus.SERVICE_UNAVAILABLE, "처리 불가");
}
}[주문 서비스] → (호출) → [업체 서비스 내부에서 재시도]
- 누가 노력하나: 업체 서비스가 내부적으로 재시도를 수행한다.
- 언제 쓰나: DB 교착 상태(Deadlock), 내부 로직 오류, 외부 API(PG사, 우체국 등) 호출 실패 등 서버 내부 문제를 극복할 때.
- 특징: 주문 서비스는 연결에는 성공한 상태. 업체 서비스가 내부적으로 처리를 재시도한다.
- 주의점: 업체 서버가 아예 다운되면 이 @Retry는 실행조차 되지 않는다.
참고: 재시도 횟수를 설정하는 두 가지 방법
yml 방식:
resilience4j.retry.configs.default.maxAttempts: 3Config 클래스 방식:
@Bean
public feign.Retryer retryer() {
return new feign.Retryer.Default(100, 1000, 3);
}Config 방식 사용 시, @FeignClient에 configuration 옵션을 추가해야 한다.
@FeignClient(
name = "company-service",
fallbackFactory = CompanyClientFallbackFactory.class,
configuration = FeignRetryConfig.class
)
public interface CompanyClient { ... }참고 : @Transactional의 범위를 주의해야 한다.
FeignClient로 외부 서버를 호출하는 것과 DB 트랜잭션은 완전히 별개의 영역이다.
모든 Feign 요청이 성공하고 마지막에 DB 저장만 실패했다면,
HTTP 통신인 FeignClient는 자동으로 롤백되지 않는다.
현재 주문 생성은 읽기 요청만 보내기 때문에, 주문 생성이 실패해도 따로 취소 요청을 보낼 필요는 없다.
문제는 쓰기 요청이 포함된 다음 케이스다.
2) 이벤트 발행/수신과 분산 트랜잭션
FeignClient 재시도가 "연결 실패" 문제라면, 이 섹션은 "DB 수정 + 이벤트 발행이 섞여 있을 때"의 원자성 문제다.
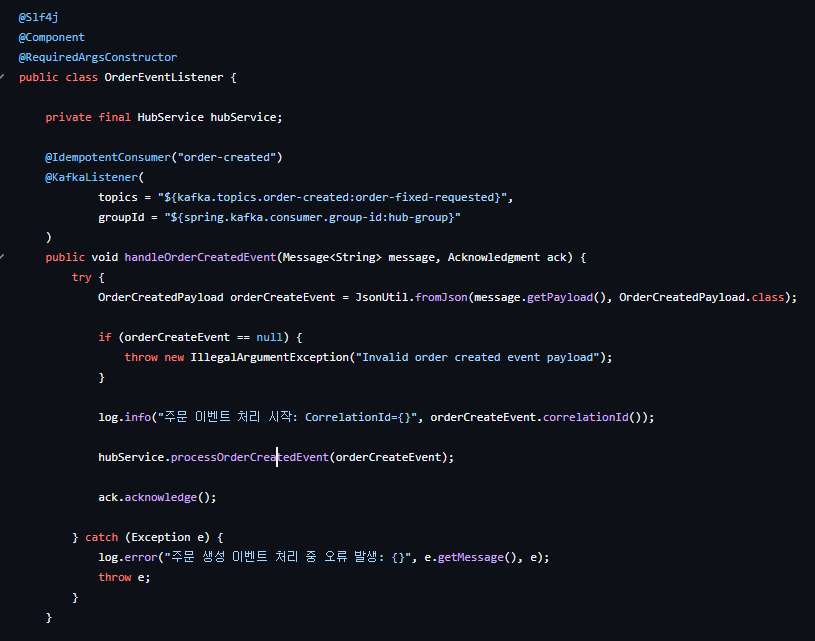
이벤트를 수신하면 processOrderCreatedEvent 메서드가 실행된다.
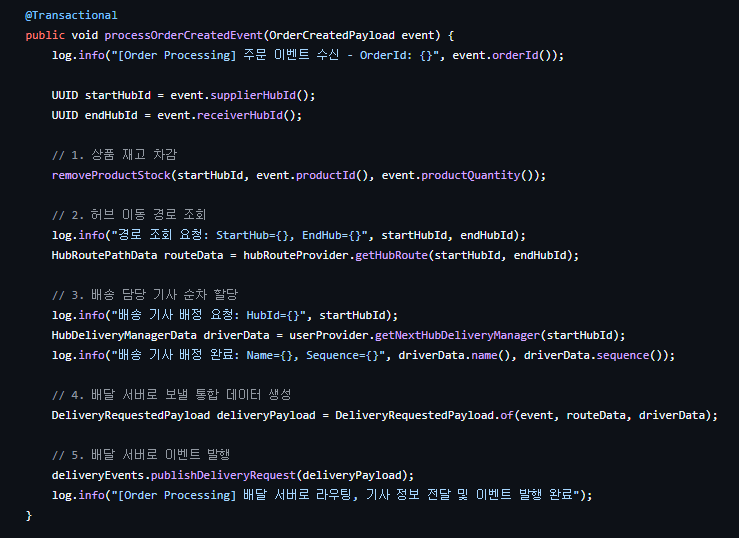
이 메서드의 실행 순서는 다음과 같다.
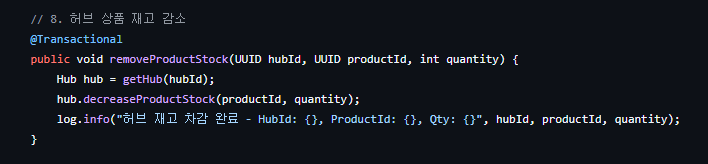
- 허브 내 재고 차감
- FeignClient GET → 허브 경로 조회
- FeignClient GET → 배송 담당자 정보 조회
- 주문서 + 허브 경로 + 배송 담당자 + 배송 순번 취합
- 배송 서버로 이벤트 발행
이 구조는 하나의 서비스 안에 DB 수정, 외부 API 호출, 메시지 발행이 모두 섞여 있다.
각 단계에서 실패할 경우 어떤 문제가 생기는지 정리하면 아래와 같다.
단계작업 내용실패 시 발생하는 문제
| 1단계 | 허브 재고 차감 | [로컬 실패] 깔끔하게 롤백. 문제없음. |
| 2~3단계 | Feign 조회 (경로, 기사) | [외부 의존성] 재고 차감은 롤백되지만, 느린 서비스로 인해 스레드 점유 → 장애 전파 가능 |
| 5단계 | 배송 이벤트 발행 | [원자성 결함] 재고는 깎였는데 배송 지시는 안 나감. 또는 유령 배송 발생 |
| 커밋 | 재고 차감 커밋 | [불일치] 이벤트는 발행됐지만 재고 차감이 롤백됨 |
결론: 단일 트랜잭션 범위 내에서 외부 시스템 호출과 DB 수정을 혼합하면 데이터 일관성을 보장하기 어렵다.
개선 방향
1. Transactional Outbox 패턴 도입
- 배송 이벤트를 즉시 발행하는 대신, 재고 차감과 같은 트랜잭션 내에서 DB의 Outbox 테이블에 함께 저장한다. 이후 별도 Message Relay가 Outbox를 읽어 이벤트를 발행함으로써 "DB는 커밋됐는데 이벤트는 안 나간" 상황을 막는다. 반대로 InBox 패턴을 통해 수신 측에서 이미 처리한 이벤트를 중복 처리하지 않도록 멱등성을 보장한다.
2. @TransactionalEventListener 활용
- TransactionPhase.AFTER_COMMIT을 사용해 DB 커밋이 완전히 성공한 후에만 이벤트가 발행되도록 분리한다. "유령 배송" 문제를 방지할 수 있다.
3. 멱등성(Idempotency) 보장
- 재시도로 동일한 이벤트가 중복 발행될 수 있다. 수신 측(배송 서비스 등)이 이미 처리된 주문 ID를 다시 받아도 중복 처리를 하지 않도록 설계해야 한다.
4. 보상 트랜잭션(Compensating Transaction) 설계
- 배송 요청이 최종 실패했을 때, 이미 차감된 재고를 원복하는 취소 이벤트를 별도로 발행한다. Saga 패턴을 적용해 결과적 일관성을 확보하는 방식이다.
결과적 일관성 관점
결과적 일관성은 "지금 당장은 일치하지 않더라도, 결국에는 일치하게 된다"는 개념이다.

위 시퀀스 다이어그램을 결과적 일관성 관점으로 읽으면 이 개념이 바로 보인다.
1단계에서 주문이 생성된 시점과 5단계에서 배송이 실제로 만들어지는 시점 사이에는 허브 서버의 이벤트 처리 시간이 포함된다. 그 사이 구간 동안 "주문은 존재하지만 배송은 아직 없는" 상태가 일시적으로 유지되고, 모든 단계가 완료돼야 비로소 두 데이터가 일치하게 된다. 이것이 결과적 일관성이 실제로 나타나는 지점이다.
문제는 이 흐름이 중간에 끊겼을 때다. 우리 팀은 주문이 취소되거나 실패하는 케이스에 대한 설계를 하지 않았다.
API 요청 실패, DB 커밋 실패, 이벤트 발행/수신 실패가 발생하면 "결국에는 일치한다"는 보장이 깨진다.
분산 트랜잭션 섹션에서 다뤘던 Outbox 패턴, 보상 트랜잭션이 바로 이 보장을 만들어주는 장치들이다.
마무리
이번 숙련 프로젝트에서 MSA 환경의 주문 도메인을 맡았었다. 기본적인 CRUD와 이벤트 처리는 완료했지만,
분산 트랜잭션 환경에서 생기는 문제들을 사전에 설계하고 대응하는 데는 부족했다.
다음 프로젝트에서는 설계 단계부터 다음 세 가지를 반드시 챙겨야겠다고 느꼈다.
- 서버 이중화를 통해 SPOF를 사전에 제거
- Outbox 패턴 + @TransactionalEventListener로 이벤트 발행의 원자성 확보
- 보상 트랜잭션(Saga 패턴)으로 실패 케이스에 대한 결과적 일관성 보장
'내배캠' 카테고리의 다른 글
| TIL - 실시간 랭킹 구현 방법 (0) | 2026.04.23 |
|---|---|
| TIL - 개발 키워드 정리 (0) | 2026.04.15 |
| TIL - 이벤트 스토밍 해보기 (0) | 2026.04.11 |
| TIL - MSA 환경에서, 엔티티가 필드로 관리해야할 범위 (0) | 2026.04.08 |
| TIL - 숙련 프로젝트 종료 후, 주문 시나리오 설계 회고 (0) | 2026.04.08 |