지도학습의 분류
- 성능 분류
- 정확도 : 전체 예측 중에서 얼마나 맞춘 비율.
예) 메일 100개 중 98개를 맞췄다면 정확도 98%. - 정밀도 : 모델이 ‘양성(스팸)’이라고 예측한 것 중에서 실제로 양성인 비율.
예) 스팸이라고 예측한 10개 중 8개가 진짜 스팸이면 정밀도 80%. - 재현율 : 실제 양성(스팸) 중에서 모델이 놓치지 않고 찾아낸 비율.
예) 실제 스팸 10개 중 9개를 찾아냈다면 재현율 90%.
- 숫자 분류
- 이산형 : 출력값이 0과 1로 표현
- 확률형 : 한 기사에 대해 정치 기사일 확률 0.7, 경제 기사일 확률 0.3
- 임계형 : 확률이 0.5 이상? 양성, 미만? 음성
- 순위형 : 높낮이로 순서 구분, 위험단계 1~5단계
로지스틱 회귀란?
이름에 회귀가 들어가지만 실제로는 분류 알고리즘이다.
특히 머신러닝 지도학습 → 분류 → 숫자 분류 중 ‘확률형’ 분류 기법이다.
로지스틱 회귀는 입력 x가 주어졌을 때:
"이 샘플이 클래스 1일 확률 p"
을 계산한다.
이름은 로짓 함수에서 유래했다.
용어 설명을 먼저 하자면,
오즈(Odds)란?
어떤 사건이 일어날 확률과 일어나지 않을 확률의 비율

예) 비 올 확률 p = 0.3
비 안 올 확률 = 0.7
=> Odds = 0.3 / 0.7
로그 오즈란?
오즈에 로그를 취한 값으로
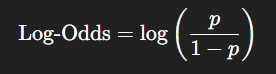
값이 -∞ ~ +∞ 의 형태로 전체 실수 범위로 확장된다.
이게 왜 중요하냐면?
선형 모델(Wx+b)은 전체 실수 범위를 출력하기 때문이다.
근데 확률 p는 0~1 사이에만 있다.
그래서 확률을 바로 선형식으로 표현할 수 없다.
그래서 확률 p 를 다음과 같이 선형으로 “펼쳐 준다”:

이 변환을 통해 확률을 선형공간으로 가져올 수 있다.
로짓(logit) 함수란?

특정 확률을 로그 오즈로 변환하는 것을 로짓 함수라고 부른다.
그리고 그 logit을 선형식으로 표현:

즉, 확률을 직접 선형으로 바꾼 게 아니라
확률 → 오즈 → 로그 오즈 → 선형식으로 바꾼 것
이게 로지스틱 회귀의 본질이다.
선형 회귀처럼 가중합을 바로 예측값으로 사용하면 확률을 해석이 불가능 하니,
확률을 선형으로 변환하기 위해
로짓 함수를 사용했다는 것이다.
이를 통해 선형회귀처럼 값을 분석할 수 있다.
우리가 최종적으로 원하는 것은 확률 p 이다.
근데 지금은 logit(p) = Wx + b 만 구한 상태.
그러므로 다시 확률 p로 되돌려야 한다.
시그모이드 함수란?
이때 사용하는 함수가 바로 시그모이드 함수(sigmoid):

시그모이드는 출력이 항상 0~1이므로
확률을 얻을 수 있다.
로지스틱 회귀의 수학적 변환 흐름
- 확률 p를 선형식으로 표현할 수 없으므로
- 확률 → 오즈 → 로그 오즈(로짓)로 바꿈
- 로짓을 선형식으로 모델링

로짓함수로 얻어낸 선형식 - 이 선형식을 다시 확률로 되돌림

실제 구현에서는 logit 계산과정이 따로 등장하지 않고
프레임워크 내부에서 자동 처리된다.
우리는 보통 이렇게만 본다:
z = Wx + b
y_hat = sigmoid(z)하지만 개념적으로는:

로지스틱 회귀의 분류
로지스틱 회귀는 이진/다중 로지스틱 회귀로 나뉜다.
이진 로지스틱 회귀 :
두 가지 범주 중 하나를 예측하는 데 사용된다.
ex) 이메일이 스팸인지? 정상 메일인지 구분하는 문제
바로 시그모이드 함수가 이진 로지스틱 회귀에 사용된다.
다중 로지스틱 회귀:
클래스가 세 가지 이상인 경우에 사용된다.
ex) 세 가지 이상의 꽃 품종을 구분, 여러 종류의 상품을 구분하는 문제 등

위는 다중 로지스틱 회귀의 로짓함수를 적용한 선형식이다.
이제 확률을 구해야 한다.
하지만 다중 로지스틱 회귀는 클래스(범주)마다 확률이 다르다.
따라서 각각의 결과에 대한 확률을 구하기 위해 시그모이드함수 대신 소프트맥스 회귀를 활용한다.

위 식을 쉽게 설명하면,
전체 확률 중, 특정 클래스에 속할 확률이다.
모든 소프트맥스의 결과값을 더하면 1이 되어야 한다.
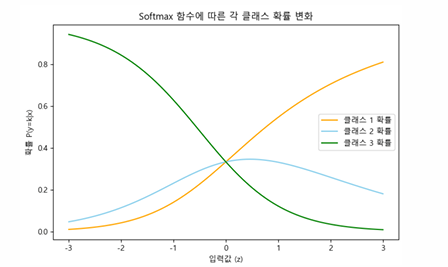
위 사진에서 x의 모든 구간에서, y의 합은 1이 된다.
'Python > 머신러닝' 카테고리의 다른 글
| 머신러닝 개념 정리) 랜덤 포레스트, 유의 확률, 카이제곱 통계량, F 통계량 (0) | 2025.11.28 |
|---|---|
| 머신러닝 개념 정리) 결정 트리, 엔트로피 지수, 지니 지수, CART 알고리즘 (0) | 2025.11.23 |
| 머신러닝 개념 정리) 서포트벡터 머신, 커널 트릭 (0) | 2025.11.22 |
| 머신러닝 개념 정리) K-최근접 이웃, 유클리드 거리, 맨해튼 거리, 체비쇼프 거리, 민코스프키 거리 (0) | 2025.11.22 |
| 머신러닝 개념 정리) 가중합, 결정계수, 선형 회귀, 다중 회귀 (0) | 2025.11.22 |